שוב יום שישי. הפרק השבוע באופטיקאסט עסק בפסיכולוגיה של השקעות נגד העדר, בעיקרון חוכמת ההמונים, ובאפקט לולהפאלוזה, שגורם לו להפסיק לעבוד. הפרק הוקלט לפני הטלטלה הקצרה שאחזה בשוק ההון ביום שני האחרון, אבל כשחושבים על זה - אולי גם עוזר להבין אותה יותר טוב. אתם מוזמנים להאזין לו כאן.
קדימה למהדורה מספר 104 -
רגעי ספוטניק
כשברית המועצות שיגרה את הלוויין הראשון לחלל באוקטובר 1957, היה לזה אפקט עמוק ומיידי על הלך הרוח באמריקה ועל המדיניות הממשלתית. האירוע הצית חרדה חברתית ברחבי ארה״ב לגבי מה שנתפס כעליונות טכנולוגית סובייטית, עם אמריקאים שעקבו אחרי הלווין בשמי הלילה והתחברו לשידורי הרדיו של ספוטניק. זה הוביל להקמת National Aeronautics and Space Administration (או: NASA) ותדלק סובסידיות ממשלתיות משמעותיות ללימודי מתמטיקה ומדעים, ואפקטיבית הצית את המירוץ לחלל. הגיוס הנרחב של האוכלוסיה האמריקאית נשא פרי 12 שנים לאחר מכן כשניל ארמסטרונג הפך לאדם הראשון שהניח את כף רגלו על הירח.
זה מתוך הספר ״מעצמות ה-AI״ (שהוזכר במהדורה 7), מאת קאי-פו לי, לשעבר בכיר במיקרוסופט וגוגל, וכיום משקיע קרן הון סיכון בבייג׳ינג. הוא הזכיר את סיפור הספוטניק, הלוויין הסובייטי ששוגר לחלל והצית תחושת דחיפות בארה״ב במהלך המלחמה הקרה, כאנלוגיה למה שקרה לדבריו בסין לאחר שאלפא-גו ניצח את אלוף העולם (מהדורה 95):
אלפא-גו השיגה את הניצחון בפרופיל-גבוה הראשון שלה במרץ 2016 במהלך סדרת חמישה משחקים מול השחקן האגדי הקוריאני לי סדול, וניצחה 4-1. בעוד שזה בקושי עורר תשומת לב בקרב אמריקאים, חמשת המשחקים משכו יותר מ-280 מיליון צופים בסין. בין-לילה, סין נזרקה לתוך קדחת AI. הסערה לא דמתה לתגובה האמריקאית לספוטניק, אבל זה הצית אש תחת קהילת הטכנולוגיה הסינית שממשיכה לבעור מאז.
כשמשקיעים, יזמים ובכירי ממשל סיניים מתרכזים כולם בתעשיה אחת, הם באמת יכולים לטלטל את העולם. אכן, סין מגדילה את ההשקעות, המחקר והיזמות סביב בינה מלאכותית, בקנה מידה היסטורי. כסף עבור סטארטאפים של AI נשפך ממשקיעי הון סיכון, ענקיות הטק, והממשל הסיני. סטודנטים סיניים כולם נדבקו גם בקדחת ה-AI, נרשמים לתכניות תארים מתקדמים, וצופים בהרצאות של חוקרים בינלאומיים בסמארטפונים שלהם. פאונדרים של סטארטאפים עושים פיבוטים, בונים מחדש, או פשוט ממתגים מחדש את החברות שלהם, במטרה לתפוס את גל ה-AI.
מה שמדהים הוא שהספר הזה יצא לאור בשנת 2018. זה שלב כל כך מוקדם! לא הרבה אחרי המצאת הטרנספורמר, או העזיבה של מאסק את OpenAI. קאי-פו לי תיאר שם את האופן שבו התפתחה תעשיית הטק הסינית, בחסות ה״Great Firewall״, שחסם את חברות הטק האמריקאיות מלפעול במדינה: בהתחלה בתור העתקה מוחלטת, ועל גביה, חדשנות מהסוג שמינפה את החוזקות הסיניות: נחישות הנדסית לעבוד קשה מסביב לשעון, ולפרוץ מחסומים, בגיבוי והכוונה ממשלתית.
מאז היו עוד כמה רגעי ספוטניק; בדומה למה שקרה למושג ״דיסראפשן״, גם השימוש המוגבר במושג ״רגע ספוטניק״ קצת מפחית מהמשמעות שלו; ריי מה טענה השבוע בטוויטר שהסיבה שכל חברות הטק הסיניות לפתע משיקות AI מתקדם מימין ומשמאל, היא, ובכן - שסין חוותה עוד רגע ספוטניק עם ההשקה של ChatGPT לפני כשנתיים. ״הייתה הרבה פאניקה בזמנו, ואנחנו רק רואים את התוצאות של מחקר ופיתוח חסר פשרות מאז״.
והשבוע, חווינו עוד אירוע שכנראה גם יירשם בספרים בתור רגע ספוטניק -
DeepSeek
האמת היא שהשבוע לא באמת קרה שום דבר; שוק המניות הגיב השבוע (עוד על זה בהמשך) באיחור לאירועים שקרו עוד לפני כן; הזכרתי בסוף המהדורה של שבוע שעבר את ההכרזה של חברת DeepSeek הסינית על R1, מודל reasoning שמזכיר את o1 של OpenAI. ההכרזה קרתה כבר ביום שני שעבר, 20 בינואר.
והתגליות שהובילו לקריסה בשוק שבוע לאחר מכן – כולל עלויות האימון של DeepSeek – נכללו כבר בהכרזה על DeepSeek V3, בסוף חודש דצמבר. ופריצות הדרך שהובילו ל V3 נחשפו כבר עם השחרור של V2, מוקדם יותר ב-2024.
בן תומפסון הסביר את זה במאמר ״DeepSeek FAQ״ שפרסם השבוע; אני חושב שההסבר הטכני חשוב, אבל מכיר בזה שהוא גם מבלבל (וחלק ממה שיצר את הפאניקה והבלבול בשוק השבוע). אתם יכולים גם לדלג עליו לפסקה האחרונה.
מודל DeepSeek-V2 [ששוחרר במאי 2024 - א.מ.] הציג שתי פריצות דרך חשובות: DeepSeekMoE ו-DeepSeekMLA. ה״MoE״ של DeepSeekMoE מתייחס ל ״mixture of experts״. מודלים מסויימים, כמו GPT-3.5, מפעילים את כל המודל גם במהלך האימון וגם במהלך inference; מסתבר, עם זאת, שלא כל חלק במודל נחוץ לנושא הרלוונטי. MoE מחלק את המודל למספר ״מומחים״ ומפעיל רק את אלו שנחוצים; GPT-4 היה מודל MoE שנהוג להאמין שכלל 16 מומחים עם בערך 110 מיליארד פרמטרים לכל אחד.
DeepSeekMoE, כפי שמומש עבור V2, הציג חדשנות חשובה עבור הקונספט הזה, כולל הפרדה בין מומחים מוגדרים יותר שהתרכזו בהתמחויות ספציפיות, לבין מומחים משותפים עם יכולות כלליות יותר. DeepSeekMoE גם הוסיפה יכולות חדשות ל load-balancing וניתוב במהלך האימון; באופן מסורתי MoE הגדיל את overhead התקשורת במהלך האימון בתמורה ל inference יעיל יותר, אבל הגישה של DeepSeek עשתה גם את האימון יעיל יותר.
DeepSeekMLA הייתה פריצת דרך אפילו יותר גדולה. אחת המגבלות הגדולות על inference נבעה מכמות הזיכרון הדרוש: צריך לטעון את המודל לזיכרון לצד כל חלון הקונטקסט. חלונות קונטסקט הם במיוחד יקרים במונחי זיכרון, מאחר שכל טוקן דורש מפתח וערך שילווה אותו; DeepSeekMLA, או multi-head latent attention, מאפשר לכווץ את ה key-value store, ולהפחית דרמטית את כמות הזיכרון שנמצא בשימוש בזמן inference.
… ההשלכות החשובות של פריצות הדרך האלה – והחלק שאתם צריכים להבין – באו לידי ביטוי עם V3, שהוסיפה גישה חדשה ל load-balancing (שהפחיתה עוד יותר את overhead התקשורת) ותחזית multi-token במהלך האימון (שצמצמה עוד יותר כל צעד באימון, ושוב הפחיתה overhead): מודל V3 היה זול בצורה מדהימה לאימון. DeepSeek טוענת שאימון המודל דרש 2,788 אלפי שעות H800 GPU, שבעלות של $2 לשעת GPU, מגיע בסך הכל ל-5.576 מיליון דולר.
DeepSeek מבהירים שאלו רק העלויות של ריצת האימון האחרונה, ולא כוללים עלויות אחרות [..] אז לא, אי אפשר לשכפל את החברה DeepSeek תמורת 5.576 מיליון דולר.
אז זה מה שקרה.
DeepSeek מצאה מספר אופטימיזציות – די מרשימות – שאיפשרו לה לאמן, בעלות יחסית נמוכה, באמצעות חומרה מוחלשת (שעומדת במגבלות הייצוא לסין), מודל (V3) שמציג ביצועים קרובים ל GPT-4 של OpenAI, עם עלויות inference נמוכות בכ-95%.
וכל זה פורסם עוד במהלך 2024.
בנוסף, ב-20 בינואר 2025, הגיעה גם ההכרזה על מודל R1, שהוזכרה פה בשבוע שעבר; הוא אומן מעל V3, וכולל יכולות reasoning. הנה ההסבר של בן תומפסון:
[...] הנקודה המרכזית היא ש R1 שימש לייצר מידע סינתטי כדי לשפר את V3; במילים אחרות, מודל AI מאמן מודל AI אחר. זו יכולת קריטית מבחינת ההתקדמות של המודלים האלה.
מה שהיה אפילו יותר מעניין כאן הוא איך R1 פיתח את יכולות ה-reasoning שלו מלכתחילה. התגלית הכי מעניינת בדו״ח הטכני של R1 הייתה ש-DeepSeek למעשה פיתחה שני מודלי R1: R1 ולצידו R1-Zero. המודל R1 הוא זה שזמין לקהל הרחב, בעוד ש R1-Zero, הוא הסיפור היותר גדול בעיניי [...]
Reinforcement Learning היא טכניקה שבה מודל למידת מכונה מקבל אוסף של דאטה ופונקציית ציון. הדוגמא הקלאסית היא אלפא-גו, שבה DeepMind נתנה למודל את חוקי המשחק גו עם פונקציית ציון שהתבססה על ניצחון במשחק, ואז נתנה למודל להבין את כל השאר בעצמו. זה באופן מפורסם התברר כהרבה יותר מוצלח מטכניקות שהתבססו על הכוונה אנושית [מהדורה 95].
מודלי שפה גדולים עד כה, עם זאת, התבססו על Reinforcement Learning with Human Feedback; בני אדם נמצאים בתמונה כדי לעזור להדריך את המודל, לבצע בחירות כשהציון הוא לא ברור מאליו, וכו׳. RLHF הייתה חדשנות המפתח שאיפשרה להפוך את GPT-3 אל ChatGPT, עם פסקאות בנויות היטב, תשובות תמציתיות שלא הדרדרו לג׳יבריש, וכו׳.
R1-Zero, עם זאת, מוריד לגמרי את חלק ה HF – זה פשוט reinforcement learning. המודל של DeepSeek קיבל אוסף של שאלות מתמטיקה, קוד, ולוגיקה, ושתי פונקציון ציון: אחת עבור תשובה נכונה, ואחת עבור פורמט נכון שהשתמש בתהליך חשיבה. יתרה מכך, הטכניקה הייתה די פשוטה: במקום לנסות להעריך צעד-אחר-צעד (תהליך מפוקח), או לבצע חיפוש של כל התשובות האפשריות (בסגנון אלפא-גו), DeepSeek עודדה את המודל לנסות מספר תשובות שונות בו זמנית ואז דירגה אותן לפי שתי פונקציות הציון.
מה שנוצר הוא מודל שפיתח יכולות reasoning ושל שרשרת-חשיבה בעצמו, כולל מה ש DeepSeek כינתה ״רגעי אה-הא״:
״תופעה מסקרנת במיוחד שהתגלתה במהלך האימון של DeepSeek-R1-Zero היא ״רגעי אה-הא״. הרגע הזה קרה בגרסת ביניים של המודל, ובמהלכו DeepSeek-R1-Zero לומדת להקצות יותר זמן חשיבה לבעיה על ידי הערכה מחדש של הגישה הראשונית שלו. ההתנהגות הזו לא רק מעידה על יכולות ה-reasoning המתפתחות של המודל, אלא גם מספקת דוגמא מקסימה של איך reinforcement learning יכולה להוביל לתוצאות מתוחכמות ובלתי צפויות.״
הרגע הזה אינו רק “aha moment” עבור המודל אלא גם עבור החוקרים שצופים בהתנהגות שלו [...]
אז זו עוד חדשנות מעניינת של DeepSeek: בניית מודל reasoning על בסיס טכניקה שבה מודל AI מאמן ומשפר מודל AI אחר, ללא מעורבות אנושית. ״אנחנו מתבוננים בתרחיש ההמראה של AI הולך ומתממש בזמן אמת״.
לולהפאלוזה
החלטת השקעה במניה של חברה לרוב מערבת מספר גורמים שמתקשרים זה לזה ... הדבר שגורם להכי הרבה צרות הוא כשמשלבים כמה כאלה ביחד, מתקבל לפעמים מעין אפקט לולהפאלוזה.
- צ׳ארלי מאנגר.
אפשר לראות איך עומס הפרטים מאפשר לאפקט לולהפאלוזה להיווצר; בתור התחלה, השמות של המודלים האלה – R1, V3 וכו׳ – הם סופר מבלבלים (בן תומפסון טען שקונבנציית השמות הזו, אות ומספר, היא הפשע השני הכי גדול שחברת OpenAI ביצעה; נגיע לפשע הראשון בהמשך). הניסיון לעקוב אחריהם, כשלעצמו, כבר דורש הרבה משאבים מנטליים, ומגדיל את מפלס החרדה.
זה לצד החרדה הכללית ששוררת מפני הסכנות שכרוכות ב-AI, ובנוסף במקרה הזה:
1. המודל הגיע מסין, מה שלכאורה מאיים על ההובלה האמריקאית ב-AI.
2. עלויות האימון נמוכות יותר, מה שלכאורה אומר שמעבדות ה-AI בארה״ב שרפו עשרות או מאות מיליארדי דולר לחינם באימון המודלים שלהם.
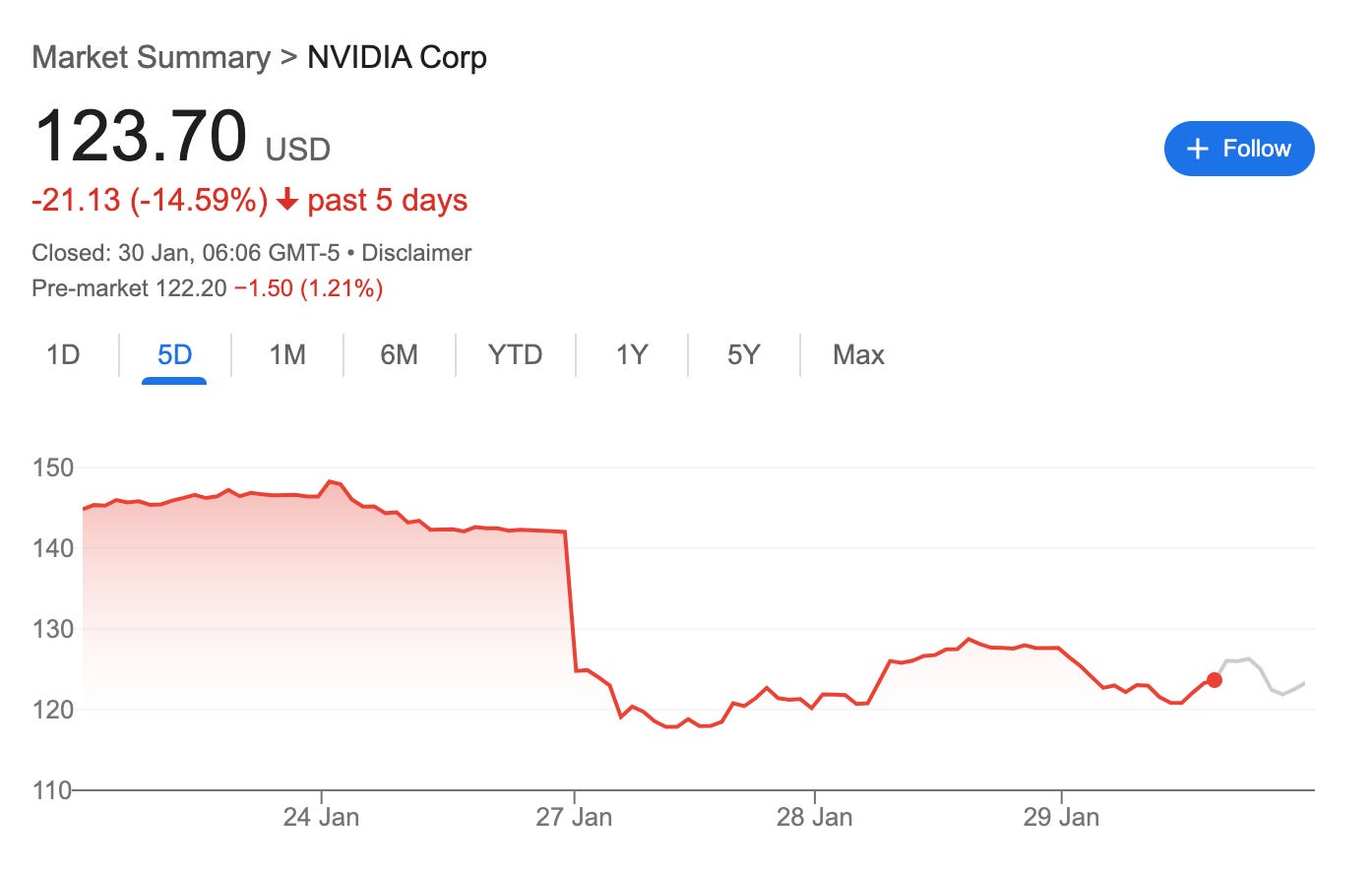
3. עלויות ה-inference הן 95% נמוכות יותר, מה שלכאורה אומר שנמצא הפיתרון למחסור במעבדים גרפיים, ובהתאמה - ההכנסות של אנבידיה יצנחו והמניה המנופחת שלה תחזור לקרקע.
שלושת המסקנות האלה הן, בלשון המעטה, לא מדוייקות (אסביר חלק מהניואנסים בהמשך). הנקודה המרתקת פה בעיניי היא משחק הטלפון-השבור שדרכו הטיעונים האלה התפשטו בטוויטר ובעיתונות הכלכלית באמריקה במהלך הסופ״ש הקודם, והדרמה שנוצרה בשוק ביום שני האחרון:
אין לי פוזיציה באנבידיה (גילוי נאות?), ובכל זאת עקבתי מקרוב, כי, האופן שבו אנשים מגיבים לאירועים מהסוג הזה - זה בעצם אחד הדברים הכי מרתקים בעיניי בשוק ההון.
למשל: אחד הדברים המעניינים כאן הוא ש-DeepSeek הגיעה להישגים האלה, למרות המגבלות של הממשל האמריקאי על ייצוא שבבים לסין. זה עורר, בהתחלה לפחות, ספקולציות שגרסו ש-DeepSeek משקרים, ולמעשה השתמשו במספר גדול של מעבדי GPU שהוברחו לסין באופן לא חוקי. הם פשוט לא יכולים להודות בזה, כי זה מנוגד לחוק. ואם זו האמת, אז הכל כאן בעצם non-event, וצריך להיות לונג אנבידיה.
אבל, בינתיים לפחות, נראה שהמתמטיקה עובדת, והאופטימיזציות של DeepSeek מאפשרות להריץ אימון של מודל כמו V3 באמצעות החומרה שהם דיווחו עליה. ויש קולות בטוויטר שדילגו על כמה שלבים בדרך, וטענו שאם DeepSeek לא הסתירו שימוש בחומרה נוספת, אז גם טיעונים 1-3 למעלה הם נכונים, והמסקנה המתבקשת היא שורט אנבידיה.
שוב, אין פה ייעוץ השקעות, אני פשוט חושב שזה מרתק!
הנטיה הזו, במצבי קיצון ולחץ, של מערכת 1 להשתלט ולהפעיל יוריסטיקות וקיצורי דרך שיפחיתו את הדיסוננס הקוגניטיבי ויחסכו בגלוקוז.
ההמלצה היחידה שלי, אם אתם הולכים לעשות פעולות בניירות ערך בתגובה לאירועים האלה, היא, להשקיע גם מאמץ של מערכת 2 בניתוח של כל הטיעונים וההשלכות. הפוסטים של בן תומפסון יכולים להיות נקודתפתיחה טובה. אני גם אנסה להתייחס לחלק מהם בהמשך המהדורה.
חזיתי שארה״ב תוביל את פריצות הדרך, אבל סין תהיה טובה ומהירה יותר בהנדסה. הרבה אנשים פישטו את זה להיות ״סין תביס את ארה״ב״. והרבה טענו שטעיתי עם GenAI. עם ההשקות האחרונות של Deepseek, אני מרגיש שצדקתי.
אבל הנה איפה שהוא לא צדק: הספר מסתיים בקריאה לא לשחזר את הדינמיקה של המלחמה הקרה; הוא טען שסין וארה״ב – שהוא כינה ״AI Superpowers״ – צריכות לעבוד יחד, ולמנף את היתרון היחסי של כל אחת, כדי לבנות יחד חזון עתידי של AI עבור טובת האנושות; זה נשמע מבטיח, אבל יש גם אלמנט של גזלייטינג באמירה הזו, כי סין מבקשת גישה לטכנולוגיה ומחקר מערבי, אבל בעצמה מונעת מחברות אמריקאיות לפעול בסין (באמצעות ה Great Firewall), ולא מכבדת זכויות קניין מערביות. העניין האחרון הגיע לשיא בסיפור גניבת מסמכי העיצוב של רכיבי זיכרון ממיקרון האמריקאית ב-2018, והגבלת הפעילות שלה בסין בעקבותיו.
הספר המצויין Chip War סוקר בהרחבה את התפתחות הדינמיקה הזו, שהובילה במהלך הקדנציה הראשונה של טראמפ להטלת מגבלות משמעותיות על חוואווי, יצרנית ציוד התקשורת והטלפונים הסינית, ולתחילת המגבלות על ייצוא שבבים, וציוד לייצור שבבים, לסין. מגבלות שרק הלכו והחריפו במהלך ממשל ביידן.
אבל בכל זאת, DeepSeek הוכיחו, לכאורה, שמגבלות הייצוא נכשלו. הזכרתי בשבוע שעבר שטיילר קוון כתב שאולי הן אפילו השפיעו לרעה, כי הן הובילו לכך שהאופטימיזציות הללו התגלו דווקא על ידי חברה סינית, שאולי תסלול את הדרך גם למדינות כמו פקיסטן, איראן או רוסיה לבנות מערכות AI מתקדמות מחוץ לפיקוח האמריקאי.
הסיפור של DeepSeek ממחיש את החוזקות הקלאסיות של ההנדסה הסינית, שקאי-פו לי ניתח בספר שלו כבר ב-2018. וכמובן שהשבוע זה גם התפתח למגוון של טייקים בנוגע לעצלנות המערבית (שלכאורה מעדיפה לזרוק יותר מעבדים גרפיים על הבעיה, במקום לעשות את העבודה הקשה של חיפוש אופטימיזציות), מה שהוביל למסקנה שסין עומדת לנצח במירוץ ה-AI. אבל אני חושב שזה גם מפספס הרבה מהתמונה: פריצות הדרך של DeepSeek נעשו באמצעות חומרה אמריקאית (מעבדי H800 של אנבידיה), על בסיס מחקר אמריקאי (טרנספורמר ומודל שפה גדול), זיקוק של מודל פתוח אמריקאי (לאמה 3), ולפי ההאשמות אולי גם ניצלו לרעה API של מודל מוביל אמריקאי אחר (של OpenAI).
DeepSeek גם לא עקפה את המודלים המתקדמים האמריקאיים – R1 הוא כנראה בר-השוואה למודל o1-mini, בעוד ש OpenAI בינתיים שחררה כבר את המודל o3 המתקדם יותר. אבל DeepSeek בהחלט הצליחה להתקרב לקדמת המירוץ. ככה גם דריו אמודיי, מנכ״ל אנת׳רופיק, הציג את הדברים בפוסט שכתב השבוע: הוא טען שהאימון של מודל קלוד 3.5 סונט עלה כמה עשרות מיליוני דולרים, והתבצע 7-10 חודשים לפני DeepSeek-V3 (וגם, לטענתו, מציג ביצועים טובים יותר במבחנים פנימיים). ירידה בעלויות בסדר גודל כזה (מכמה עשרות מיליוני דולרים ל-6 מיליון בתוך 7-10 חודשים) היא צפויה, ולא מתקרבת לנרטיב שנוצר, כאילו ״הסינים עשו ב-6 מיליון דולר מה שנדרש לחברות AI אמריקאיות מיליארדי דולרים כדי לבנות״.
בהקשר למגבלות ייצוא, אמודיי טוען שיידרשו מיליוני שבבים ועשרות מיליארדי דולרים של השקעה במהלך 2026-2027 כדי לבנות סופר-בינה מלאכותית, וכדי לוודא שזה נבנה בארה״ב, הוא קורא להגביל את סין מלהשיג כמויות חומרה בקנה מידה כזה.
במובן מסויים, זה מזכיר את זלנוגראד – סיליקון ואלי הסובייטית – שבאופן עקבי ניסתה להעתיק במדוייק כל התקדמות בפיתוח הסמיקונדקטורס האמריקאיים; באופן אירוני, זה מה ששמר על היתרון האמריקאי במלחמה הקרה (מהדורה 92):
באופן ביזארי, מנטליות ה״תעתיקו את זה״ יצרה מצב שבו מסלול החדשנות של סמיקונדקטורס סובייטים הוכתב על ידי ארה״ב. אחת התעשיות הכי רגישות של ברה״מ תפקדה, אם כן, כמו שלוחה לא מנוהלת היטב של הסיליקון ואלי.
גם במקרה של DeepSeek, ההסתמכות על חומרה אמריקאית ומודלים אמריקאיים, מכתיבה את ההתקדמות של מודלי ה-AI הסיניים על אותו מסלול חדשנות כמו המודלים האמריקאיים; ההבדל העיקרי הוא שהמנטליות בסין מעודדת חדשנות הנדסית וחשיבה מחוץ לקופסא, דברים שנאסרו בזמנו בברה״מ.
אז האתגר עבור התעשיה האמריקאית הוא גדול יותר לעומת המלחמה הקרה, אבל המפתח להובלה בטווח הארוך הוא זהה: להישען על היתרונות של סיליקון ואלי. להתקדם מהר יותר, להגיע לפריצות דרך מוקדם יותר, לייצר יותר חדשנות, ולשמור על ההובלה.
זו גם הייתה הקריאה של בן תומפסון: הוא טען שארה״ב לא צריכה להתמקד במגבלות ורגולציה, ובמקום זה – ללכת בכיוון ההפוך ולהתמקד בניצחון. ״אם נבחר להתחרות עדיין נוכל לנצח, ואם זה יקרה, תהיה לנו חברה סינית להודות לה״.
רגע הגוגל
אני חושב שרגע ה Deepseek הוא לא באמת רגע ספוטניק, אלא יותר כמו רגע גוגל.
[...]
ספוטניק הראה שהסובייטים יכולים לעשות משהו שארה״ב לא יכלה (״כח חדש ומטיל אימה״). הם לא פרסמו לאחר מכן את כל הפרטים הטכניים וחצי מהארכיטקטורה. הם רק הראו שזה יכול להתבצע. עם Deepseek, אם אני זוכר נכון, מעבדה בברקלי קראה את המאמר ושכפלה את התוצאות שלהם בקנה מידה קטן בתוך יום אחד.
זו הסיבה שאני אומר שזה כמו רגע הגוגל ב-2004. גוגל הגישה תשקיף לקראת הנפקה ב-2004, וחשפה לעולם שהם בנו קלאסטר מחשב-על באמצעות אלגוריתמים מבוזרים כדי לחבר יחד מחשבי קומודיטי בנקודת הביצועים-לדולר הכי משתלמת על עקומת העלות. זה היה בניגוד לכמעט כל חברת טק אחרת, שבזמנו רק קנתה מה שלמעשה היה מיינפריימים יותר ויותר גדולים, תמיד בקצה הכי יקר של עקומת העלות.
זה מתוך טוויט מעניין של אישאן וונג, שאני ממליץ לקרוא את כולו; ייתכן שההשוואה לספוטניק היא אכן מופרזת. וההשוואה היותר נכונה היא לפריצות הדרך סביב האופן שבו גוגל בנתה את התשתיות של אינדקס החיפוש שלה בתחילת הדרך. הוא סיכם במילים:
אין סיבה לחשוב שאנבידיה ו OpenAI ומטא ומיקרוסופט וגוגל והשאר גמורות. בטח, Deepseek היא שחקן חדש ומרשים, אבל זה לא קורה כל שבוע בעולם של AI? אני בטוח שסאם וזאק, עם הכח של סאטיה מאחוריהם, יוכלו להבין מה לעשות. כולם הולכים להעתיק את זה בתוך כמה חודשים והכל נהיה זול יותר. ההשלכה האמיתית היחידה היא שהאוטופיה/חורבן של AI עכשיו קרובים מתמיד.
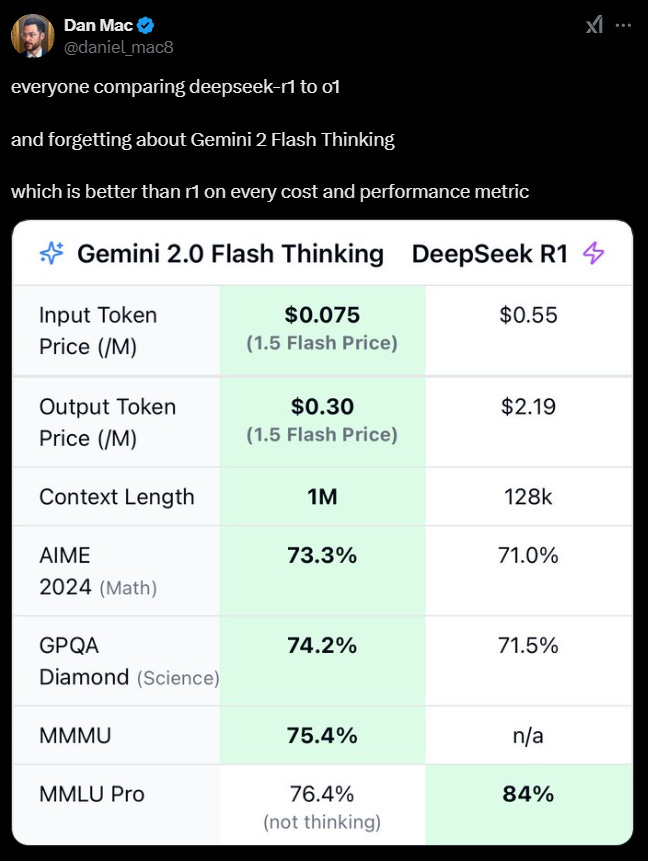
ואם כבר מדברים על גוגל! יש סיכוי שאלמלא DeepSeek, ההשקה האחרונה של גוגל, Gemini Flash Thinking, הייתה מקבלת קצת יותר תשומת לב, ואולי במקום רגע ה-Deepseek, היינו מכנים גם את האירוע הנוכחי בתור רגע גוגל; כמו שדן מאק כתב בטוויטר, המודל החדש של גוגל זול יותר אפילו מ-R1 – לכאורה המודל היעיל ביותר – ומציג ביצועים טובים יותר!
יכול להיות שחלק מהאופטימיזציות ש DeepSeek מצאה, כבר נמצאו בשלב מוקדם יותר ע״י מהנדסי התשתיות של גוגל; אין דרך לדעת, כי גוגל לא מפרסמת פרטים לגבי האופן שבו היא מאמנת את המודלים שלה. וזה אולי מצביע על עוד צד חיובי בהתפתחות האחרונה: DeepSeek כן פרסמו דו״ח טכני מפורט, שכנראה יאפשר לשאר התעשיה לזנק קדימה יחד, ולא להשאיר את גוגל בפער גדול מהאחרים. באופן אירוני, זה היה אמור להיות הייעוד המקורי של OpenAI – למנוע מגוגל בלעדיות על מודלי AI מתקדמים – והמקרה הזה רק מדגיש את הביקורת על הסטיה שלהם מהכיוון המקורי, ועל כך שהבינה המלאכותית ש-OpenAI בונה היא כבר ממש איננה פתוחה. זהו אגב, בקווים כלליים, הפשע הראשון הכי גדול שהחברה ביצעה.
באופן מעניין, הזכרתי בעבר את פריצות הדרך של גוגל בתחילת הדרך, ואיך הן בדיעבד היוו את הסוף של סאן מיקרוסיסטמס – יצרנית השרתים הדומיננטית בעידן שלפני כן – בהקשר של, ובכן, לא אחרת מאשר אנבידיה! סאן מיקרוסיסטמס הייתה מניית חומרה שהרקיעה שחקים בתקופת בועת הדוט-קום (באופן אירוני, הפרסומת שלהם מ-1999 אמרה שהם ״שמים את הדוט בדוט-קום״), ואחד מהסמלים של הקריסה שבאה לאחר מכן. השרשור שכתבתי בזמנו ניסה לנתח את ההשוואה שלהם למצב של אנבידיה היום; באנלוגיה - כמו שרגע הגוגל של 2004 סימל את הסוף של סאן, האם רגע הגוגל הנוכחי יסמן את הסוף של, ובכן - סאן הנוכחית? כלומר, לכאורה, של אנבידיה?
גילוי נאות: לונג גוגל
פרדוקס ג׳בונס
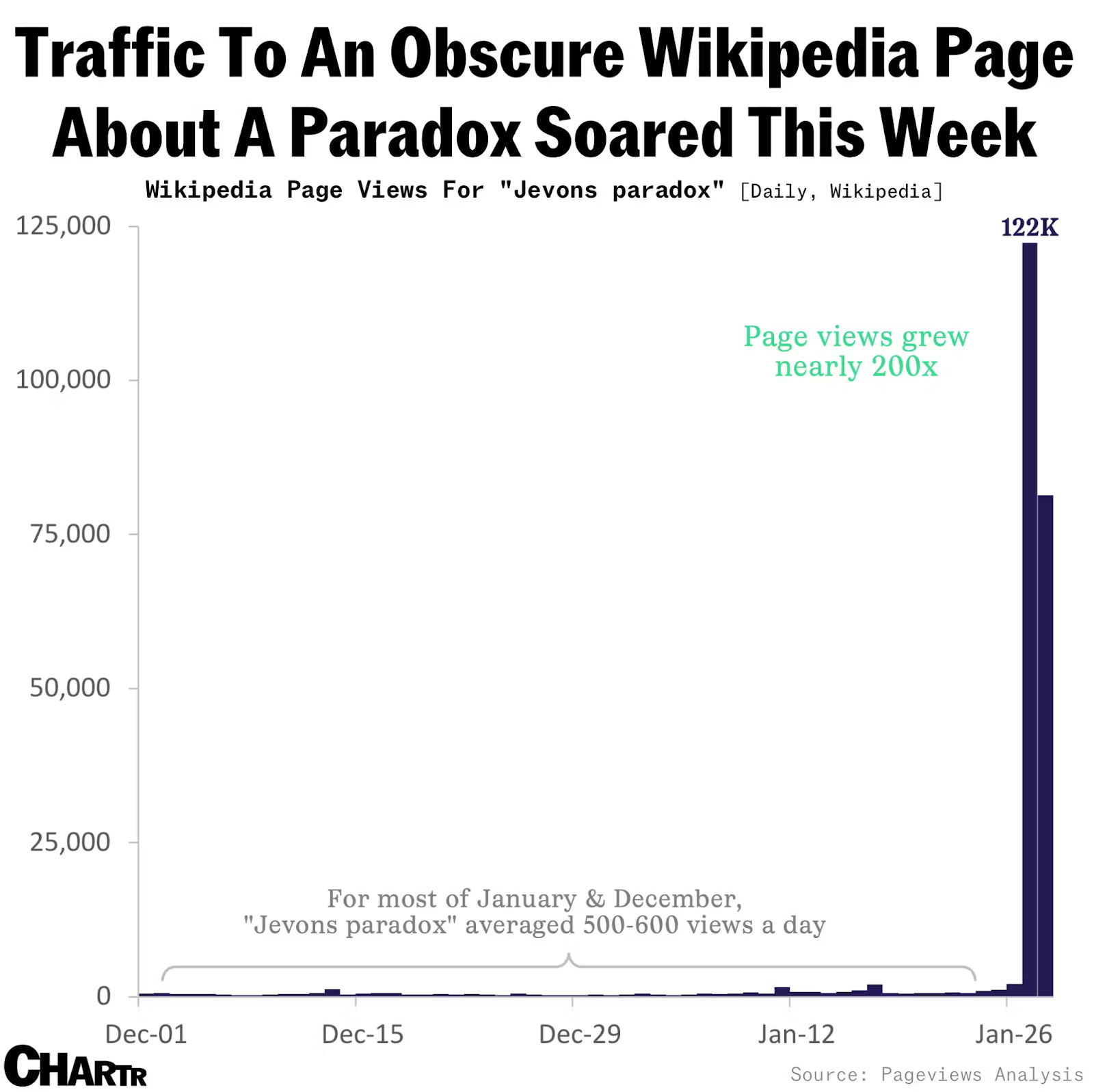
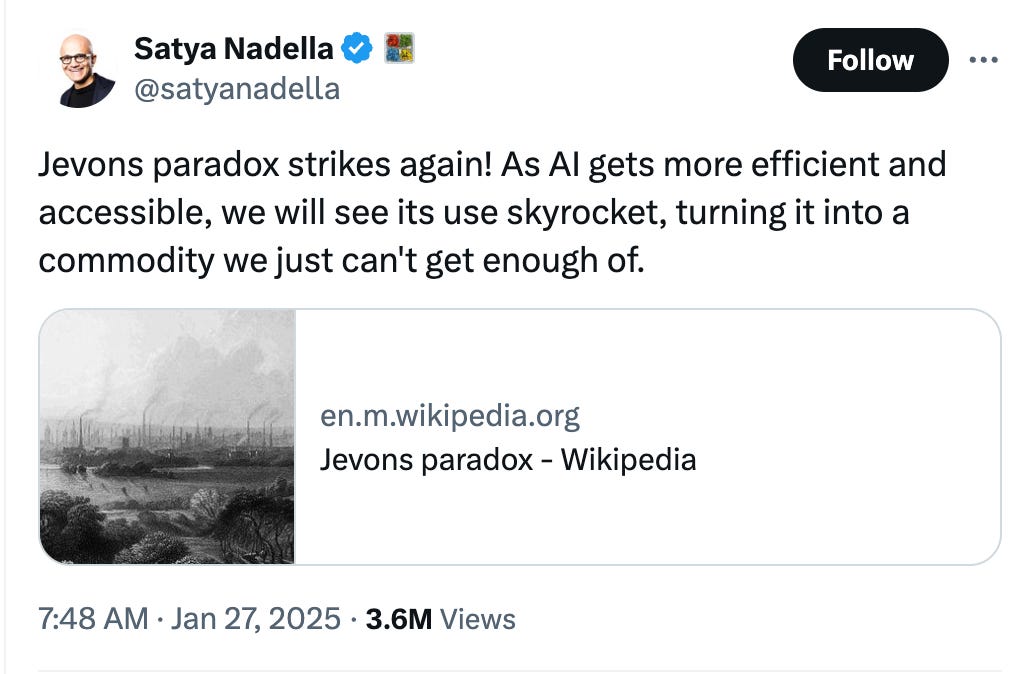
עמוד הויקיפדיה של ״פרדוקס ג׳בונס״ התפוצץ מטראפיק השבוע, לאחר שסאטיה נאדלה צייץ את הלינק ביום שני האחרון. אבל אתם כמובן לא הייתם צריכים לנהור לשם יחד עם כולם, כי כבר דיברנו פה על פרדוקס ג׳בונס, ועל ההקשר שלו ל-AI, במהדורה 32 (ובפרק 40 של אופטיקאסט):
… הפרדוקס של ג׳בונס, שנקרא על שם הכלכלן וויליאם סטנלי ג׳בונס שהבחין בו לראשונה בספרו מ-1856 ״שאלת הפחם״, קובע שכשמשהו נהיה יעיל יותר, אנשים צורכים יותר ממנו. ג׳בונס הבחין שכשמנוע הקיטור נהיה יעיל יותר – כשהוא היה יכול לעשות יותר עם פחות פחם – צריכת הפחם למעשה גדלה. אנשים לא השתמשו במנועי קיטור כדי לבצע את אותם דברים יותר בזול; הם התחילו להשתמש במנועי קיטור כדי לעשות יותר דברים.
באנלוגיה, כשאינטל רכבה על חוק מור, מספר הטרנזיסטורים במעגל המשולב הכפיל את עצמו מדי שנתיים, וכח חישוב נהיה זול יותר – זה לא שהסתפקנו בפחות מעבדים של אינטל. להיפך! הביקוש התפוצץ, כי התחלנו לעשות יותר ויותר דברים עם מחשבים.
… מחשוב מציית לחוק הגז. כלומר, זה ממלא את החלל הפנוי כפי שמוגדר על ידי המשאבים הזמינים (הון, חשמל, תקציבים, וכו׳). כפי שראינו ב CMOS, PCs, ריבוי-ליבות, וירטואליזציה, מובייל ומקרים אחרים; להפוך משאבי מחשוב לזמינים באופן נרחב במחירים נמוכים באופן קיצוני, יוביל להתרחבות עצומה, לא להתכווצות, של השוק. AI יהיה בכל מקום בעתיד והיום, זה בסדרי גודל יקר מדי כדי לממש את הפוטנציאל המלא. אני זוכר את חוויית דפדפן האינטרנט הראשונה שלי - וואו. ועכשיו - זה בכל דקה או שניה של כל יום אם אתם טינאייג׳רים. תגובת השוק היא שגויה, הפחתת העלות של AI תרחיב את השוק. היום אני קונה אנבידיה ומניות AI ושמח להרוויח ממחירים נמוכים יותר.
אני לא משוכנע כמוהו באטרקטיביות של המניה של אנבידיה, אבל אני מסכים עם הרעיון הכללי: כל התרחישים שדמיינו לגבי סוכנים מבוססי AI רק יאיצו, כשאפשר להשתמש אפילו ביותר סוכנים, בעלות יותר נמוכה. וכמו שהתקשינו לדמיין דברים כמו אובר או נטפליקס או אינסטגרם, או כל שאר הדברים שנבנו הודות לכך שהעלות השולית של מחשוב ירדה אפקטיבית לאפס, גם הרבה דברים שמרגישים כמו מדע בדיוני היום יוכלו להתממש אם העלות השולית של inference תתקרב גם היא לאפס.
כמו שצבי מושוביץ׳ העיר בסרקסטיות בטוויטר, המניה של אנבידיה יורדת על רקע החדשות שהשבבים שלה הם מאד שימושיים. החברה היא עדיין היצרנית המובילה של מעבדים גרפיים מתקדמים, והאלמנטים העיקריים שמרכיבים את החפיר שלה – בעיקר, חבילת התוכנה CUDA, והיכולת לבנות קלאסטר אפקטיבי שמכיל כמות עצומה של מעבדים – עדיין רלוונטיים. המניה שלה, מצד שני, עלולה לשקף ציפיות גבוהות מדי במחיר הנוכחי.
תרחיש בועת ה-AI שתיארנו כאן, התבסס על בניית תשתיות שתקדים יותר מדי את הבניה של מוצרים ומקרי שימוש אמיתיים. האנלוגיה היא הפרישה של תשתיות פייבר במהלך בועת הטלקום (מהדורה 63), שכמעט ולא נעשה בהן שימוש. זה לקח עוד כמה שנים עד שהגיעו יוטיוב ופייסבוק והקלאוד. יכול להיות שגם במקרה הזה, פרדוקס ג׳בונס יתממש בטווח הארוך, אבל — אולי — בדרך לשם נחווה עודף היצע שיוביל לפאניקה וקריסה.
במילים אחרות: האופטימיות של פאט גלסינגר לגבי המניה של אנבידיה, עלולה להתברר כמופרזת, בדומה לאופטימיות – המופרזת בדיעבד – שהייתה לו לפני ארבע שנים, לגבי היכולת שלו לשנות את גורלה של אינטל.
משהו שלא הזכרתי עדיין הוא את סיפור ההקמה של DeepSeek; הנה מתוך כתבה במגזין פורצ׳ן:
הפאונדר של DeepSeek ליאנג וונפנג לא מתאים לפרופיל המקובל של חלוץ בינה מלאכותית. בניגוד למנכ״ל OpenAI סאם אלטמן, למשל, הוא לא יזם מסיליקון ואלי.
במקום זה, ליאנג מגיע מעולם הכספים. לאחר שסיים את לימודיו באוניברסיטת זנג׳יאנג, הוא הקים את קרן הגידור High-Flyer ב-2015 ושילב AI באסטרטגיות המסחר שלה כדי לחזות טרנדים בשוק ולעזור בהחלטות השקעה.
לפי הפייננשל טיימס, הוא החל לקנות אלפי מעבדים גרפיים של אנבידיה ב-2021 – לפני שממשל ביידן החל להגביל ייצוא של שבבי AI לסין – בתור פרוייקט צדדי. בזמנו, התייחסו לזה בתור תחביב מוזר שלא נראה שיילך לשום מקום.
זו סגירת מעגל כל כך… נהדרת. פרוייקט ה-LLM של DeepSeek החל לפני ארבע שנים כתחביב צדדי, שנועד לשפר את אסטרטגיות המסחר של קרן גידור; השבוע, אותו פרוייקט הוביל לטלטלה בשוק, שממחישה את הכשלים של הבינה האנושית בשוק ההון, ו, אולי, גם את הפוטנציאל שיש שם עבור בינה מלאכותית.
דו״חות: צ׳ק פוינט דיווחה על צמיחה של 6% בהכנסות ב-2024, לצד כניסת נדב צפריר לתפקיד המנכ״ל והמעבר של גיל שויד לתפקיד היו״ר. טסלה פספסה את תחזיות הרבעון הרביעי ודיווחה על 8% ירידה בהכנסות ממכירת רכבים. מטא הביסה את התחזיות ודיווחה על שיא בהכנסות, על רקע שיפור בביצועי הפרסום הודות ל-AI. מיקרוסופט הביסה את התחזיות אבל דיווחה על צמיחה איטית-מהצפוי בשירות הענן. ASML הביסה את תחזיות הרווח, במה שמתפרש כאינדיקציה לביקוש חזק לשבבי AI. מובילאיי עם תחזית מאכזבת ל-2025, ההכנסות ב-2024 נחתכו ב-20%. אינטל הביסה את התחזיות אבל הציגה תחזית מאכזבת. אפל דיווחה על ירידה במכירות מכשירי אייפון ועליה בהכנסות משירותים.
״משקיעי הון סיכון נמשכים למקצועות שבלוניים כגון חשבנאות, מרכזי שירות לקוחות, וניהול נכסים. יזמי טק גייסו מאות מיליוני דולרים כדי לבנות מחדש את העסקים האלה עם כלי AI שישפרו את הרווחיות שלהם … הסטארטאפים גם מאמצים את אחת הפרקטיקות החביבות על וול סטריט: רול-אפ … הרבה מההון שהסטארטאפים האלה מגייסים נועד לממן רכישה של עסקים, ש״מגולגלים יחד״ לאופרציה אחת …״
אתם מוזמנים גם לעקוב אחריי בלינקדאין, וואטסאפ, טוויטר או פייסבוק. ואם עדיין לא נרשמתם לבלוג - אפשר לעשות את זה כאן כדי לקבל את הניוזלטר בכל יום שישי בבוקר ישירות למייל:
תזכורת: הבלוג הזה הוא למטרות לימודיות בלבד. אין לראות באמור לעיל ייעוץ השקעות. מסחר במניות מלווה בסיכונים רבים. אנא קראו את הדיסקליימר המלא כאן.



מושקע ומעניין מאוד. תודה.