

מהדורה 7 - בן תומפסון על שיעורי בית עם בינה מלאכותית, פול גרהאם, טאלב ומבחן טיורינג ההפוך, עלויות האימון של מודלי שפה גדולים, מעצמות הבינה המלאכותית, תשומת לב היא כל מה שאתם צריכים
״ייתכן שמעכשיו נחמיא לקטע טקסט במילים - *זה* לא היה יכול להיכתב על ידי בינה מלאכותית״
הקורס הראשון שלקחתי בסטנפורד (לפני קרוב לעשור) היה בבינה מלאכותית, ופרופסור אנדרו אנג׳י פתח את השיעור הראשון בניסיון להציג יישומים שונים של AI וליצור התלהבות סביב כמה זה חשוב. כנראה שבשיעור שהוא העביר השבוע הוא לא היה צריך להתאמץ הרבה כדי ליצור מוטיבציה. ההתרגשות מ Generative AI הגיעה לשיא בשבוע שעבר כשחברת Open AI הכריזו על צ׳אט שמבוסס על מודל השפה שלהם GPT. אני חושב שזה נושא מרתק שמצדיק מהדורה חגיגית בבלוג הצעיר.
שני בונוסים לפני שנעבור למהדורה: סאם אלטמן, מנכ״ל Open AI ובעבר הנשיא של YCombinator, התארח לקראת ההשקעה בפודקאסט של קרן גריילוק וחלק שם כמה מהמחשבות שלו לגבי ״העידן החדש״ שהבינה המלאכותית עומדת ליצור (לינק).
ורגע לפני שנתחיל, בחרתי שתי אנקדוטות מבין הדוגמאות שהציפו את טוויטר בשבוע האחרון: אחת היא מנקודת מבט של מתכנת בטוויטר שנדרש להציג לאילון מאסק את התרומה שלו בשבוע האחרון, אבל הוא לא עשה כלום. הוא משתמש בצ׳אט כדי למצוא רעיון לפרוייקט ולכתוב את הקוד עבורו, ככה שירשים את אילון מאסק. עוד אחת מרשימה היא מתכנת שהשתמש בצ׳אט כדי לדמות מכונה וירטואלית, והריץ פקודות לינוקס שונות שיצרו קבצים ותיקיות.
דברים שנתקלתי בהם השבוע
בן תומפסון על שיעורי בית עם בינה מלאכותית
ההכרזה על ChatGPT תפסה את בן תומפסון בדיוק כשעזר לבת שלו עם שיעורי בית בהיסטוריה, וזו הייתה הזדמנות מצויינת בשבילו לנסות אותו על השאלה. הוא קיבל תשובה מנוסחת היטב שמלווה בסימוכין וציטוטים, אבל הייתה שגויה לגמרי. הוא הסביר גם למה זה הגיוני - המודל הוא סטטיסטי, והוגה הדיעות מהשאלה (תומאס הובס) לרוב מוזכר בטקסט בסמוך להוגי דיעות אחרים. כשמדובר במרחק של מספר משפטים או פסקאות מודל השפה מעריך בהסתברות גבוהה שהאישים והרעיונות קשורים אחד לשני, אבל קשה לו להבין איזה רעיון מיוחסים לאיזה אדם, וקל לו לערבב ביניהם.
זה הוביל את בן לבחון את הטכנולוגיה הזו מנקודת מבט של הישענות עליה להכנת שיעורי בית. בהרבה מובנים זה דומה למחשבון. ההבדל הגדול הוא שמחשבונים הם דטרמיניסטיים - הם יודעים לבצע מטלות מאד ספציפיות, אבל התשובות שלהם תמיד נכונות. בינה מלאכותית לעומת זאת, היא הסתברותית. אפשר להיעזר בה למגוון הרבה יותר רחב של מטלות, אבל בהרבה מקרים מקבלים תשובה שגויה. היו במאמר כמה דוגמאות נהדרות שממחישות את זה כמו היכולת להעריך בצורה נכונה את הפלט של קטע קוד בפייתון (ואפילו יותר מהר מהזמן שהיה לוקח להריץ את הקוד על לפטופ), אבל מצד שני הצ׳אט התבלבל בשאלה אריתמטית שקל למחשבון לבצע.


המסקנה של תומפסון: ״התפקיד של בן האנוש בעבודה עם AI הוא לא להיות המתשאל, אלא להיות העורך.״ הרעיונות עצמם יגיעו מפרץ יצירתיות של המוח האנושי, שלאחר מכן ייעזר ב AI ככלי שיהפוך את זה לתוכן יפה ואיכותי. בדיוק כמו שפסלים מודרנים משתמשים במכונות או ציירים מודרניים משתמשים בתוכנה.
פול גרהאם, טאלב ומבחן טיורינג ההפוך
טאלב נתן כותרת אחרת לבעיה שבן תומפסון הצביע עליה. הבינה המלאכותית מייצרת טקסט שנשמע אינטלגנטי וסמכותי, אבל הרבה פעמים מלא בשגיאות. טאלב מכנה את התופעה הזו בתור מילוליות (verbalism).
המשמעות הישירה של המילה הזו היא שימוש בשפה ריקה מתוכן. טאלב צירף טיוטה של פרק שהוא מנסה לכתוב על הנושא בה הוא מציג מגוון של דוגמאות שהוא מחשיב כוורבליזם, למשל שימוש במונחים שיש להם ספקטרום רחב כמו ״ליברלי״, ״מודרני״ או ״פופוליסט״ בצורה בינארית (משהו הוא כזה או שאינו כזה). עוד דוגמאות הן שימוש לא נכון במונחים שיש להם הגדרה מדעית מאד מדוייקת כמו ״קורלציה״ או ״תנודתיות״, או שימוש במונחים רחבים עם הגדרה שרירותית לא ברורה כמו ״הציביליזציה המערבית״ או ״תרבות המזרח״. טאלב יוצא נגד הקלות שבה לטענתו אפשר לייצר בולשיט מוחלט שמבוסס על נפנוף ידיים, אבל נתפס בעיניי הרבה אנשים כתוכן אינטלגנטי ומשכנע.
לטענתו זה בעיקר סוג הטקסט שהבינה המלאכותית יודעת לייצר, מאחר והאלגוריתם עדיין מבוסס על תוויות שמייצגות חשיבה שטחית.
פול גרהאם התנסח בצורה די מעודנת כשהסביר איך הוא רואה את אותה תופעה:
אם AI הופך כתיבה בינונית שאינה מכילה רעיונות חדשים לקומודיטי, האם זה יעלה את ה״מחיר״ של כתיבה טובה שכן מכילה אותם? אפשר לשאוב עידוד מההיסטוריה. עבודת-יד זכתה ליותר הערכה ברגע שזו כבר לא היה ברירת המחדל. והסיבה שאנשים יותר מעריכים דברים שנעשו בעבודת יד היא חלקית בגלל שאיכות עקבית אך בינונית שמאפיינת מכונות יצרה בסיס רחב להשוואה. ייתכן שעכשיו נחמיא לקטע טקסט במילים ״זה לא היה יכול להיכתב על ידי AI.״
טאלב אמר בדיוק את אותו רעיון, אבל בסגנון הישיר והמלגלג שאופייני לו. עכשיו בעזרת הבינה המלאכותית אנחנו יכולים לבצע את ״מבחן טיורינג ההפוך״, שעליו כתב בספרים המוקדמים שלו:
אקראיות יכולה לעזור בנושא הזה. מאחר שיש דרך נוספת והרבה יותר משעשעת להבחין בין מי שמפטפט לבין אדם חושב. אתה יכול לפעמים לשכפל משהו שעלול בטעות להיחשב כיצירה ספרותית עם מחולל מונטה קרלו, אבל זה בלתי אפשרי ליצור כתיבה מדעית באופן אקראי. רטוריקה יכולה להיבנות באופן אקראי, אבל לא ידע מדעי אמיתי. זה היישום של מבחן טיורינג לבינה מלאכותית, רק בכיוון ההפוך. מהו מבחן טיורינג? המתמטיקאי הבריטי הגאון, האקסצנטרי, ומייסד ענף המחשבים אלן טיורינג המציא את המבחן הבא: מחשב יכול להיחשב כאינטלגנטי אם הוא יכול (בממוצע) לשכנע בן אנוש להאמין שהוא (המחשב) גם בן אנוש. ההיפך גם צריך להיות נכון. בן אנוש יכול להיחשב כ״לא-אינטלגנטי״ אם אפשר לשכפל את סגנון ההתבטאות שלו באמצעות מחשב, שאנחנו יודעים שאינו בעל אינטלגנציה, ולשכנע אדם אחר שזה נכתב על ידי אותו אדם.
העלויות של אימון מודל שפה גדול
יש סיבה שחברות כמו OpenAI ו StableAI גייסו לאחרונה סכומי כסף גדולים לפי שווי של מיליארד דולר או יותר - כוח המחשוב שנדרש ליצור את המודלים האלה עולה הרבה מאד כסף. זה אמנם פחות יקר ממה שזה היה בעבר (וזו אחת הסיבות לפרץ ההשקות האחרון), אבל זה עדיין דורש הרבה יותר מימון מאשר להתחיל מערכת SaaS (בינתיים).
הנה מאמר שניסה להעריך כמה עולה לאמן מודל LLM כמו של OpenAI.
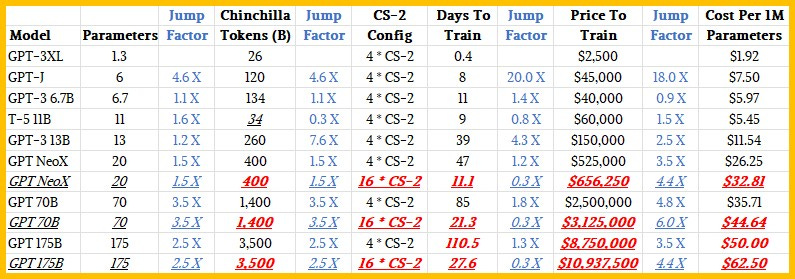
המודלים מסודרים בטבלה מהקטן למתוחכם יותר. ככל שהמודל גדול יותר מבחינת מספר הפרמטרים שהוא מכיל, ייקח יותר זמן לאמן אותו, והמחיר יהיה יותר יקר. הוא גם יהיה יותר מוצלח מבחינת היכולות והביצועים שלו. הנקודה שמצאתי מעניינת כאן היא שהזמן שנדרש לאמן את המודל עולה יותר לאט מאשר מספר הפרמטרים, אבל עלות האימון עולה הרבה יותר ככל שמספר הפרמטרים גדל. זה בגלל שהמחיר פר מיליון פרמטרים עולה בעצמו בקצב די מהיר, כנראה בגלל שיש הרבה יותר יחסים ומורכבות בין הפרמטרים ככל שמגדילים את המספר שלהם.
חלק מהמהפיכה שיצר AWS היה בהורדת החסמים לבניה של סטארטאפ - במקום לגייס כמה עשרות אלפי דולרים בתור תנאי התחלה, כל אחד יכל לשכור שרת בעלות חודשית נמוכה כדי להתחיל לבנות משהו. אני סקרן האם יתפתח בסוף מודל דומה גם סביב אימון של מודל AI מתוחכם, שיאפשר להוריד את העלות ההתחלתית לאפס. משהו כמו ״לשכור מודל״, או לאמן מודל עם מספר מוגבל של פרמטרים רק בשביל להתחיל לחפש algo-market-fit. אני לא בטוח אם זה בכלל יהיה הגיוני, או שאני יותר מדי מנסה לכפות את האנלוגיה ל SaaS.
מה אתה קורא?
קאי-פו לי עבד על פרוייקטי AI באפל עד שמונה להקים את מחלקת המחקר של מיקרוסופט בסין. בהמשך היה המנהל של גוגל-סין עד שהפעילות של גוגל בסין נסגרה1 ב-2009, ומאז הוא מנהל קרן הון סיכון בסין.
לספר שפרסם ב-2018 היו שני חלקים מעניינים בעיניי, ולקח לי קצת זמן להבין איך הם מתחברים למסר אחד. החלק הראשון היה מאד אינפורמטיבי וכלל סקירה מעניינת של התפתחות הטכנולוגיה בסין - האינטרנט המקביל של טנסנט, ביידו ועליבאבא (הספר פורסם ב-2018 ולא מכיל את הפרטים העדכניים על בייטדאנס/טיקטוק, ההשפעות של קוביד, או מלחמת הצ׳יפים עם אמריקה). את הניצחון המוחץ של אלפא-גו (האלגוריתם של גוגל) על האלוף הסיני הוא מכנה ״רגע הספוטניק״ של סין, בהשוואה לשיגור המוצלח של הספוטניק שבריה״מ ביצעו בתחילת שנות ה-60׳, ושדחף את קנדי להכריז על פרוייקט אפולו במטרה להנחית אדם על הירח. לי מספר שאלפא-גו סימנה לא רק את ניצחון המכונות אלא גם את ניצחון חברות הטק המערביות, ושסין הבינה שהיא צריכה להצטרף למירוץ ולהשלים פערים. משם יש ניתוח מעניין של הגישה והתרבות השונות בסין, שבעיניי היה מאיר עיניים כי הרבה נוטים להסתכל על סין דרך פרספקטיבה מערבית, בלי להבין הרבה מההיסטוריה והניואנסים במדינה ובאיזור (בתור ישראלי אני יכול להזדהות עם כמה זה מעצבן לשמוע דיעות על המצב במדינה שלי מאמריקאים שלא מכירים את הפרטים).
פרק 7 הרגיש כמו שינוי כיוון מאד מפתיע עבורי. אחרי שעבר לנתח את ההתקדמות בבינה המלאכותית ומה התחזיות שלו לגבי השלבים השונים וההשפעה על מקומות עבודה ומקצועות העתיד, בפרק שבע קאי-פו לי שיתף בסיפור מאד אישי שבו גילו אצלו סרטן, בשלב די מתקדם על פי האבחון.

קאי-פו לי מסביר שרופאים מאבחנים את הצילום והבדיקות באמצעות היוריסטיקות שמותאמות למגבלות המח האנושי. לכן החלוקה השרירותית לארבעה שלבים, וההסתמכות על מספר מצומצם של פרמטרים כדי לסווג את הגידול לאחת מארבע הקטגוריות. הגידול הסרטני לא באמת מתקדם בין ארבעה שלבים אלא מתפתח באופן רציף, ואלגוריתם AI גם היה יכול להסתכל על מספר הרבה הרבה יותר גדול של פרמטרים (כמו שראינו למעלה, GPT מאומן על מיליארדי פרמטרים).
למזלו של קאי-פו לי, המקרה שלו היה זה שהיורסיטיקה פספסה. אחרי תקופה מלחיצה עבור אישתו והילדים שלהם, התברר שהגידול שלו היה בשלב הרבה יותר קל, והטיפול הרפואי הצליח. החוויה הזו הביאה אותו לכמה מסקנות לגבי בינה מלאכותית: בתור התחלה היא הראתה לו את הפוטנציאל של שימוש בבינה מלאכותית כדי לבצע יותר טוב מטלות שבעבר בוצעו על ידי מומחים אנושיים.
בנוסף הוא מספר שתקופת הטיפול והאשפוז הייתה מלחיצה וקשה עבורו. הצוות הרפואי היה מקצועי מאד וביצע עבודה נהדרת שבסוף גם הצליחה לרפא אותו, אבל הם לא נתנו מענה לטלטלה הרגשית שעברה עליו. היה לו מזל שאשתו ובני משפחה אחרים בילו איתו הרבה זמן והציעו לו תמיכה. זה הביא אותו למסקנה השניה: בני אנוש לא יוכלו לתקשר ישירות עם האלגוריתם. הם עדיין יזדקקו לבן אנוש אחר שיודע להפעיל את האלגוריתם בצורה מעולה, ובנוסף יוכל להציע להם חוויית אינטראקציה אנושית, ולמשל להביע דברים כמו אמפתטיה וחמלה - שהאלגוריתם לא יידע לבצע.
עבורי זו הייתה תובנה די מרעננת כשהספר יצא ב-2018, ובמובן מסויים היא משתלבת גם עם הרעיון שבן תומפסון הציג במאמר שלו שהזכרתי למעלה.
המלצה מהעבר
האם ה Transformer יתברר כהמצאה הטכנולוגית המכוננת שאפשרה את גל ה- S-Curve שעליו ירכב העידן החדש בבינה מלאכותית?
בפוסט ״נקודות מבט על S-Curves״ הזכרתי את המודל של ״אסימפטוטות בלתי נראות״:

בכל שלב יש אילוץ או מחסום כלשהו שמונע עוד שיפור בביצועים, עד שהמחסום מוסר באמצעות איזשהי המצאה ואז יש שיפור מאד מהיר בביצועים, עד שנתקלים ב״תקרה״ חדשה. אפשר להלביש את הדוגמאות מהסעיפים הקודמים (ספינות קיטור, רכבים, סמארטפונים) על המודל הזה, לנסות לראות מה היו החסמים וההמצאות שפתרו אותן, ולהבין יותר טוב למה אימוץ של טכנולוגיות חדשות מתרחש בגלים כאלה.
ההמצאה שאפשרה את הגל הנוכחי של Generative AI היא הטרנספורמר, שגוגל הציגה במאמר שפירסמו ב-2017 תחת השם ״Attention Is All You Need”. [אני יודע שמאמרים אקדמיים יכולים להיות מאיימים ומשעממים, אבל זה מאמר די קצר ואדם שלא מפחד להסתכל על משוואות כנראה יצליח לקרוא אותו בלי המון מאמץ]. המאמר הוא יחסית קצר וממוקד, אבל למרבה המזל גוגל גם פירסמו פוסט פשוט יותר בבלוג שלהם שמסביר את החידוש:
בניגוד (לרשתות נוירונים - א.מ.), הטרנספורמר מבצע רק מספר קטן וקבוע של צעדים (שנבחר באופן אמפירי). בכל צעד, הוא מיישם מנגנון תשומת לב עצמי שבאופן ישיר יוצר מודלים של היחסים בין כל המילים במשפט, ללא קשר למיקום שלהן. בדוגמא הקודמת ״I arrived at the bank after crossing the river״, כדי לקבוע שהמשמעות של המילה ״bank” היא גדה של נהר ולא מוסד פיננסי, הטרנספורמר יכול ללמוד לשים לב מיד למילה ״river״ ולבצע את ההחלטה הזו בצעד אחד. למעשה, במודל התרגום אנגלית-צרפתית שלנו אנחנו רואים בדיוק את ההתנהגות הזה.
יותר בפירוט, כדי לחשב את הייצוג הבא של מילה נתונה - למשל ״bank” - הטרנספורמר משווה אותה לכל מילה אחרת במשפט. התוצאה של ההשוואות האלה היא קביעת ציון מבוסס תשומת-לב לכל מילה אחרת במשפט. ציוני תשומת-הלב האלה קובעים כמה כל אחת מהמילים אחרות צריכה לתרום לייצוג הבא של ״bank״. לדוגמא, המילה “river” שמשמשת להבהיר את המשמעות הנכונה של של “bank” תוכל לקבל ציון תשומת-לב גבוה כשנחשב ייצוג חדש למילה “bank”. ציוני תשומת-הלב משמשים כמשקלים כדי לחשב ממוצע מבוסס-משקל של ייצוגי כל המילים שהוזנו לתוך רשת מחוברת-במלואה, כדי לייצר ייצוג חדש למילה “bank״, שישקף את העובדה שהמשפט מדבר על גדה של נהר.

זה אולי נשמע טכני ובנאלי, אבל הטכניקה הזו איפשרה לאמן רשתות נוירונים בצורה מקבילה באמצעות מעבדים מודרניים מהירים כמו GPU (או מעבד ה TPU של גוגל), מבלי לבצע מספר גדול של צעדים כדי לשלב מידע ממקומות בקלט שלא קרובים אחד לשני. וחמש שנים אחרי המצאת האלגוריתם הזה אנחנו כבר יכולים לייצר בזכותו תמונות וקטעי טקסט באיכות גבוהה ויצירתית באמצעות פקודות טקסטואליות.
השאלה שאני סקרן לגלות לגבי הטרנספומר היא האם המודלים שנראה בעוד עשור או יותר עדיין יהיו מבוססים על טרנספורמרים, ובדיעבד זו תתברר כהמצאה מהפכנית כמו ה-CPU של אינטל ב-1971 שאליו מייחסים את תחילת עידן המחשוב? האם אנחנו בפתחו של גל S-Curve משמעותי וארוך בזכות האפשרויות שהטרנספורמר פתח? או שהטרנספורמר ייזכר כעוד אבן ביניים שהיינו צריכים לדרוך עליה בדרך לגילוי של טכניקות הרבה יותר מתוחכמות, כמו שפופרת הוואקום שהייתה המצאה מהפכנית שאפשרה את הדור הראשון של מחשבים, עד שהטרנזיסטור החליף אותה בגלל התכונות העדיפות שלו.
לינק לפוסט ההסבר, לינק למאמר המלא
תודה שקראתם את הרהורי יום שישי שלי השבוע!
אם עוד לא נרשמתם, אפשר להירשם כאן כדי לקבל את הניוזלטר בכל יום שישי בבוקר ישירות למייל:
אתם מוזמנים גם לעקוב אחריי בטוויטר ובפייסבוק.
גוגל פרסמו סרט דוקומנטרי על הסיבות שהביאו אותם להפסקת הפעילות בסין וההקמה של פעילות האבטחה וזיהוי האיומים